There are a couple of ways to cancel a fetch call. The new AbortController API is designed specifically for this purpose. Another, albeit less effective, way is to use a timeout promise in combination with Promise.race; less effective because this doesn’t actually cancel the ongoing network request, just that the results get ignored. The latter is a popular way to do cancellation before AbortController. There are libraries that help with this, but there are subtle memory leaks that show up with some of the implementations.
A naive implementation
A simple, buggy implementation might look like this:
const request = fetch(url, options).then(response => response.json());
const timeout = new Promise((_, reject) => {
setTimeout(() => {
reject(new Error('Timeout'));
}, 10000)
});
Promise.race([ request, timeout ]).then(response => {}, error => {})The error callback could have a network error if request fails, or the timeout error object if the request doesn’t finish in 10 seconds.
The first issue you might spot here that the timeout is not cleaned in neither of the callbacks. This means that for 10 seconds, all the resources in that function, which get closed over by the Promise constructor’s function will stay in memory until the timer gets expired. If there are lots of requests in a short period, and the responses are large enough, this might even induce a crash of the Node process as it hits the memory limit (< 2 GB at least as of Node 11).
A naive implementation, improved
Clearing the timeout in the fetch handlers will avoid the guaranteed bloat:
const request = fetch(url, options).then(response => response.json());
let timeoutId = null;
const timeout = new Promise((_, reject) => {
timeoutId = setTimeout(() => {
reject(new Error('Timeout'));
}, 10000)
});
Promise.race([ request, timeout ]).then(
response => {
timeoutId && clearTimeout(timeoutId)
// handle response
},
error => {
timeoutId && clearTimeout(timeoutId)
// handle error
})Note: It’s a mistake to miss out the clearTimeout call in both the handlers. Missing out on either will still introduce the memory leak in the opposite case. Alternatively, the new .finally handler on Promise API can be used to call the clearTimeout just once as a final step, no matter which branch the execution takes.
At work, we faced this issue at nearly 10000 requests per second, and a timeout setting set to 4 seconds. Since it only showed up at that scale, it’s kind of hard to debug too!
Better version
A way to avoid closing over the context is to separate out promise creation into a function. But it may not be easy/possible to pass the timeout ID out to the caller, which is required for clearing the timer entry. A JavaScript class (or the equivalent non-modern version) can solve this problem cleanly.
First up, the class that encapsulates the timeout:
class Timeout {
constructor(config = {}) {
this.timeout = config.seconds || 10000;
this.timeoutID = undefined;
}
get start() {
return new Promise((_, reject) => {
this.timeoutID = setTimeout(() => {
reject('request timedout');
}, this.timeout);
});
}
clear() {
this.timeoutID && clearTimeout(this.timeoutID);
}
}The start() function here uses the new getter syntax, which turns the function into a property access, which means, (new Timeout()).start internally calls the start() function and returns the output. This is strictly not necessary, but just a syntax sugar that makes the usage a little cleaner, especially when reading code.
The usage of this class would look something like this:
// This is why there's a separate "start" function that returns the
// promise in question. The timer is started only when the Promise.race
// starts, rather than when the instance is created.
const timeout = new Timeout({ seconds: 1000 })
const request = fetch(url, options).then(response => response.json())
return Promise.race([ request, timeout.start ]).then(success => {
timeout.clear();
// handle response
}, error => {
timeout.clear();
// handle error
});
/*
Or, using finally:
return Promise.race([ request, timeout.start ]).then(success => {
// handle response
}, error => {
// handle error
}).finally(_ => { timeout.clear() });
*/This has the benefit of encapsulating the access to the timeout ID away from the actual call site of fetch, and there’s clearer picture of the code flow compared to the older inline anonymous function version.
I’ve profiled the memory retention information between GCs for the first and the last implementation, and here’s a summary:
Before:
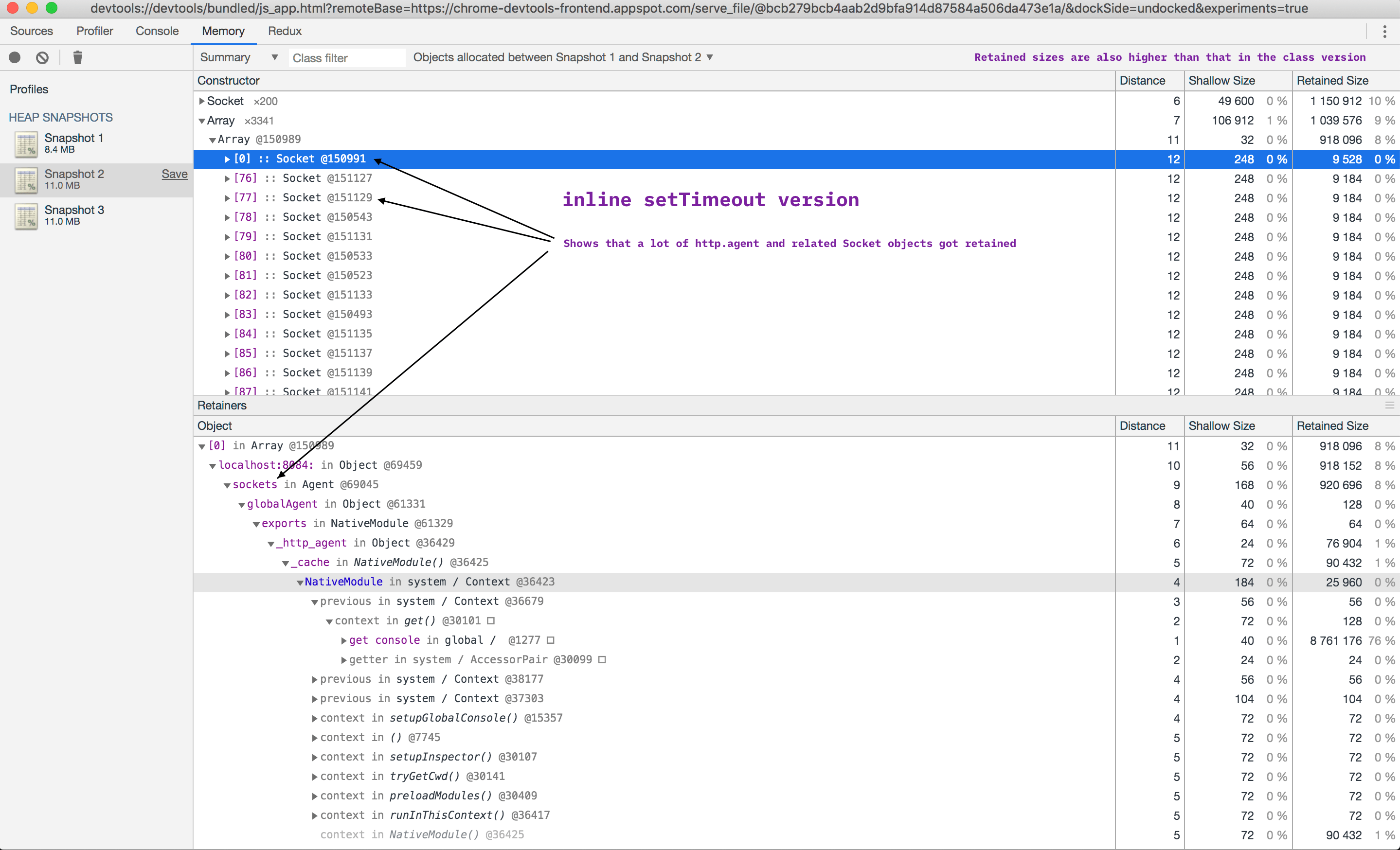
After:
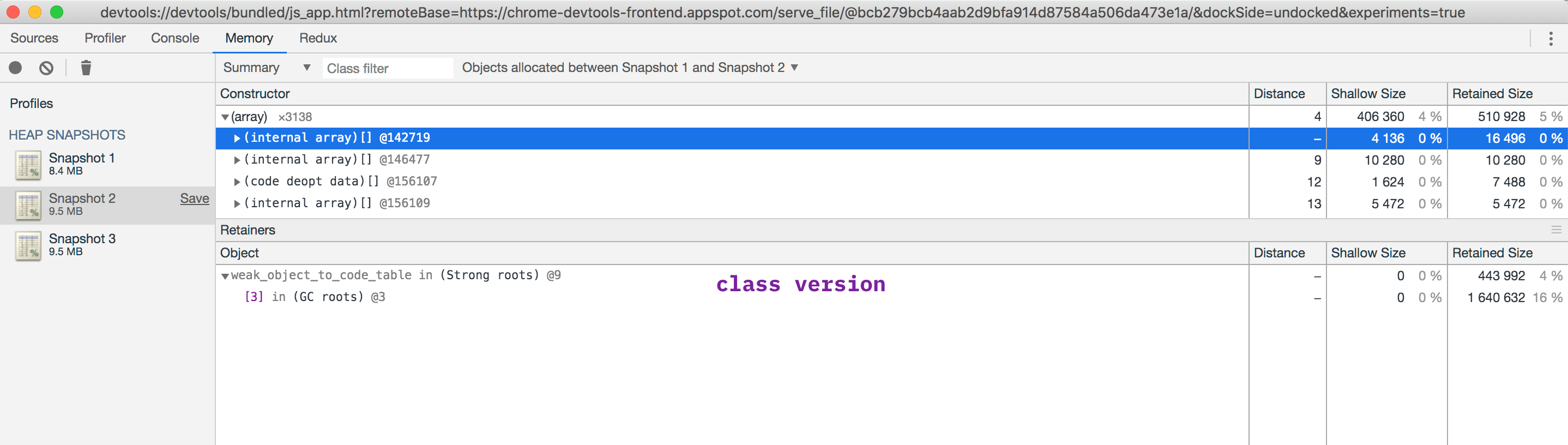
The methodology used:
- On a cold start: trigger a GC and take the first snapshot
- Make 100 requests per second for 10 seconds, with 100 connections, using the wrk2 tool
- Take another snapshot
- Trigger a GC
- Take the third snapshot
Whatever objects got allocated between snapshot 1 and 2 represent the normal allocations as requests get handled, which ideally should get reclaimed after the requests stop ( normal operation of the garbage collected ). When objects get retained between multiple garbage collection runs, there is increased pressure on the garbage collector which, incidentally, also handles memory allocation when the application needs it. If there is a memory cap, the program simply crashes. Object retention doesn’t necessarily mean there’s a memory leak, but the effect in both cases might end up being the same.